A deep technical exploration of Amazon Nova Sonic’s speech foundation model: how it unifies ASR, LLM and TTS into a single, event-driven, bidirectional stream API for real-time voice interactions. Understand its session and event flows (session init, audio/text/tool content, completion events), how it handles “barge-in”, adapts tone and expressivity in speech generation, and the implications for latency, context preservation, and building more natural voice experiences.

Figure 1: Amazon Nova Sonic
Traditional approaches in building voice-enabled applications involve complex orchestration of multiple models, such as:
- Speech Recognition (ASR) to convert speech to text
- Large Language Models (LLMs) to understand and generate responses
- Text-To-Speech (TTS) to convert text back to audio
This fragmented approach not only increases development complexity but also fails to preserve crucial acoustic context and nuances like tone, prosody, and speaking style that are essential for natural conversations.
Speech Foundation Models unifies speech understanding and speech generation into a single model, to enable more human-like voice conversations in AI applications. This unification enables the model to adapt the generated voice response to the acoustic context (e.g., tone, style) and the spoken input, resulting in more natural dialogue.
The Amazon Nova Sonic model provides real-time, conversational interactions through bidirectional audio streaming. It implements an event-driven architecture through the bidirectional stream API.
This event-driven system enables real-time, low-latency, multi-turn conversations. Key capabilities include:
- Streaming ASR and TTS in one flow, eliminating latency from chained services.
- Adaptive voice generation, modulating tone, pace, and expressivity in sync with user speech.
- Graceful interruptions, where the system can detect when a user cuts in (“barge‑in”) and seamlessly switch focus.
The bidirectional stream API consists of these three main components:
- Session initialization: The client establishes a bidirectional stream and sends the configuration events.
- Audio streaming: User audio is continuously captured, encoded, and streamed as events to the model, which continuously processes the speech.
- Response streaming: As audio arrives, the model simultaneously sends output event responses:
- Tool use events for function calling
- Text response event for conversation transcription
- Audio chunks response event for spoken output
The overall events flow:
-
Format of Input Audio Capture: 16kHz sample rate, mono channel is preferred.
-
Events that need to be sent in the same order for initiating the session and starting audio streaming:
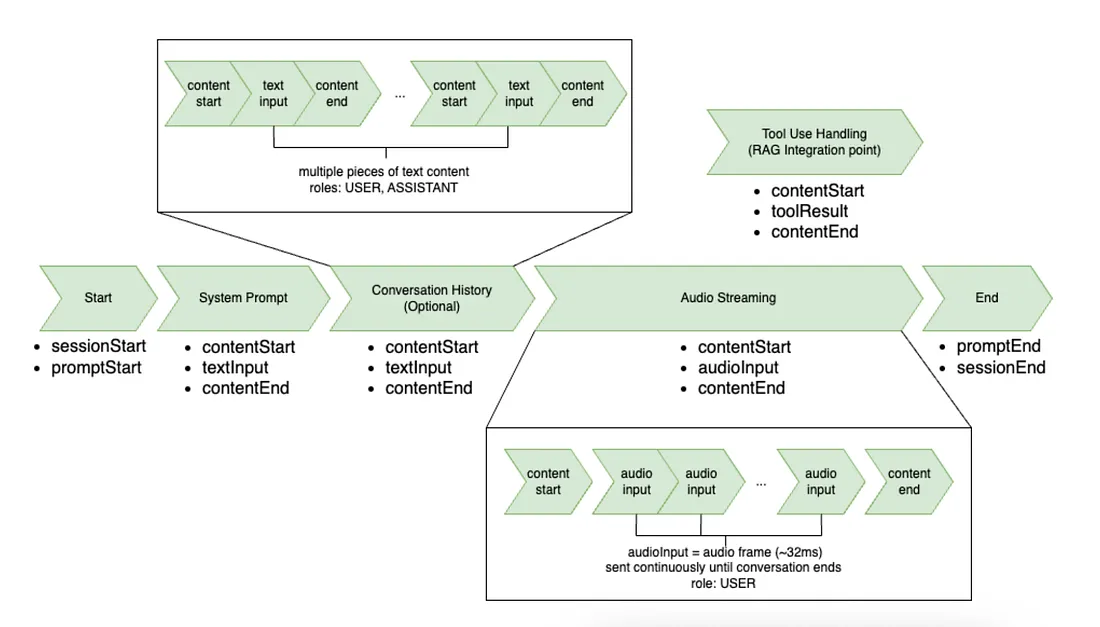
Figure 2: Amazon Nova Sonic Input Events Flow
a. Session Start Event
- Set up the session configuration (e.g., inference configurations like
maxTokens,topP,temperature, etc.)
b. Prompt Start Event
- Set up the text output, audio output, tool use output and tool configurations.
c. Audio/Text/Tool Content Start Event
- Specifies the role (
SYSTEM,ASSISTANT,USER,TOOL, etc.) and content type (audio/text) and configurations.
d. Audio/Text/Tool Content Event
- Audio Content Event: Streams the user’s mic input (16 kHz, mono) in base64-encoded audio chunks.
- Text Content Event: Used when sending system prompts as text or multiple message conversations of role
USERandASSISTANT. - Tool Result Content Event: Used when sending tool results back to Nova Sonic.
e. Content End Event
- Marks the end of the most recent content block (audio, text or tool).
- When the Amazon Nova Sonic model responds, it also follows a structured event sequence.
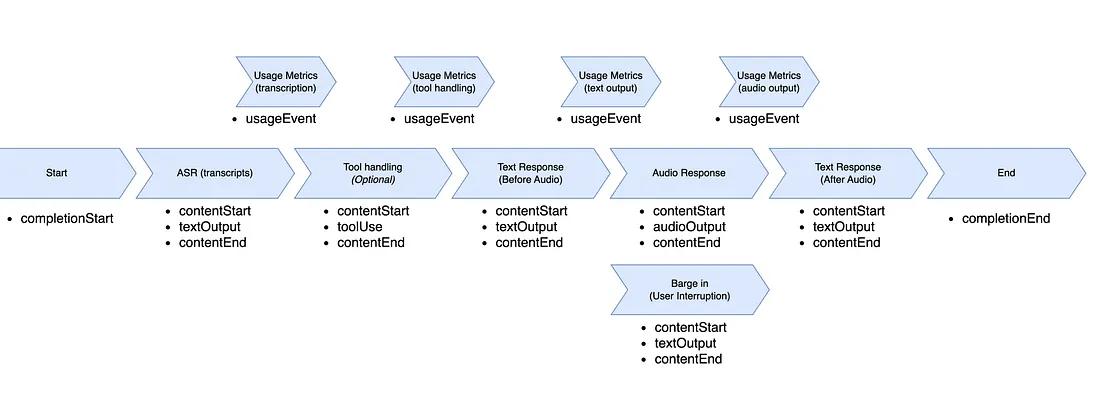
Figure 3: Amazon Nova Sonic Output Events Flow
a. Completion Start Event
- Marks the beginning of the model’s response.
b. Content Start Event
- Opens each part of the response: transcript, tool call or audio each with its own contentId.
c. Text Output Event (ASR Transcripts)
- Provides real-time speech-to-text transcripts.
d. Tool Use Event (Tool Handling)
- When the model needs to call a tool or function, it emits a tool-use event with name and parameters.
- Your client must execute the tool and send results back via input events.
e. Audio Output Event (Audio Response)
- Delivers base64-encoded audio chunks of TTS speech, all sharing the same contentId.
f. Content End Event
- Indicates the end of a response block and provides a stopReason.
g. Completion End Event
- Finalizes the entire response cycle.
- Events for ending session:
a. Prompt End Event
- Signals the end of this conversational thread.
b. Session End Event
- Closes the entire session reliably.
- Barge In Detection:
- When the
stopReasonincontentEndevent isINTERRUPTED.
- Usage Metrics:
- The
usageEventis used to track input and output speech and text tokens.
By understanding the base64 encoding of both audioInput (user speech) and audioOutput (model response), as well as the structured sequence of events with their defined roles and states, we can implement a robust, low-latency streaming voice application using Amazon Nova Sonic.
Prompt Engineering for Speech Foundation Model:
Requires a different prompting approach than standard text-based models. We should optimize content for auditory comprehension rather than for reading comprehension.
System Prompt steers the model’s output style and lexical choice. It can’t be used to change speech attributes such as accent and pitch. The model decides those speech characteristics based on the context of the