Retrieval-Augmented Generation (RAG) has rapidly evolved into multiple variants, each designed to tackle different challenges of grounding LLMs in external knowledge. In this article, we break down seven of the most widely used RAG “flavors”, from standard and advanced setups to graph-based, multi-modal, and self-reflective approaches and explain their unique strengths, trade-offs, and real-world use cases.
Much like new JavaScript libraries seem to emerge almost daily, fresh flavors of Retrieval-Augmented Generation (RAG) are appearing at a rapid pace. Keeping up with all these developments can be overwhelming, yet most widely used approaches are built on a few fundamental methods or their variants. In this article, we will go through these fundamental approaches in detail.
But what is RAG?
RAG is a technique that combines:
-
a retrieval component: pulling in relevant texts (documents, passages, etc.) from an external knowledge base or corpus
-
plus a generative component: a large language model (LLM) that uses the retrieved material as part of its input to generate responses.
RAG helps models be more accurate, up‐to‐date, grounded in facts, and reduces “hallucinations” (making up information).
The name “Retrieval-Augmented Generation” (RAG) was coined in the 2020 paper Retrieval‐Augmented Generation for Knowledge-Intensive NLP Tasks by Patrick Lewis et al. The term captures precisely the idea: generation (text generation) that is augmented by retrieval from external data.
What problem is it solving?
Large Language models are brilliant, but they forget. They get stuck in the past. And sometimes, when asked something new, they simply make things up.
These models, huge stacks of neural networks, trained on massive oceans of text, had learned much. But all their wisdom was frozen in time, captured in parameters. Updating them was like trying to rewrite the memories of a giant elephant: expensive, slow, and imperfect.
Why This Was Such a Big Deal?
-
Timeliness: Facts change. New events happen. Instead of retraining a model every time, one could update the external corpus.
-
Accuracy & Trust: Reducing hallucinations (those times the model makes things up) by anchoring outputs in retrieved texts.
-
Modularity & Efficiency: The retriever + generator split meant researchers could improve one without completely discarding the rest.
-
Explainability: You can see what the model “looked up” gives human oversight a chance.
Afterwards: The Evolution
Ever since RAG’s “official debut,” lots of researchers and engineers have built on it:
Variants in how retrieval works (dense vs sparse methods, better search indexes, better embedding strategies, etc.). Ways to decide when and what to retrieve during generation.
Lets try to understand the 7 most widely used flavours of RAG:
- Naive (Standard) RAG
- Advanced RAG
- Mult-modal RAG
- Agentic RAG
- SQLRAG
- GraphRAG
- Self-Reflective RAG
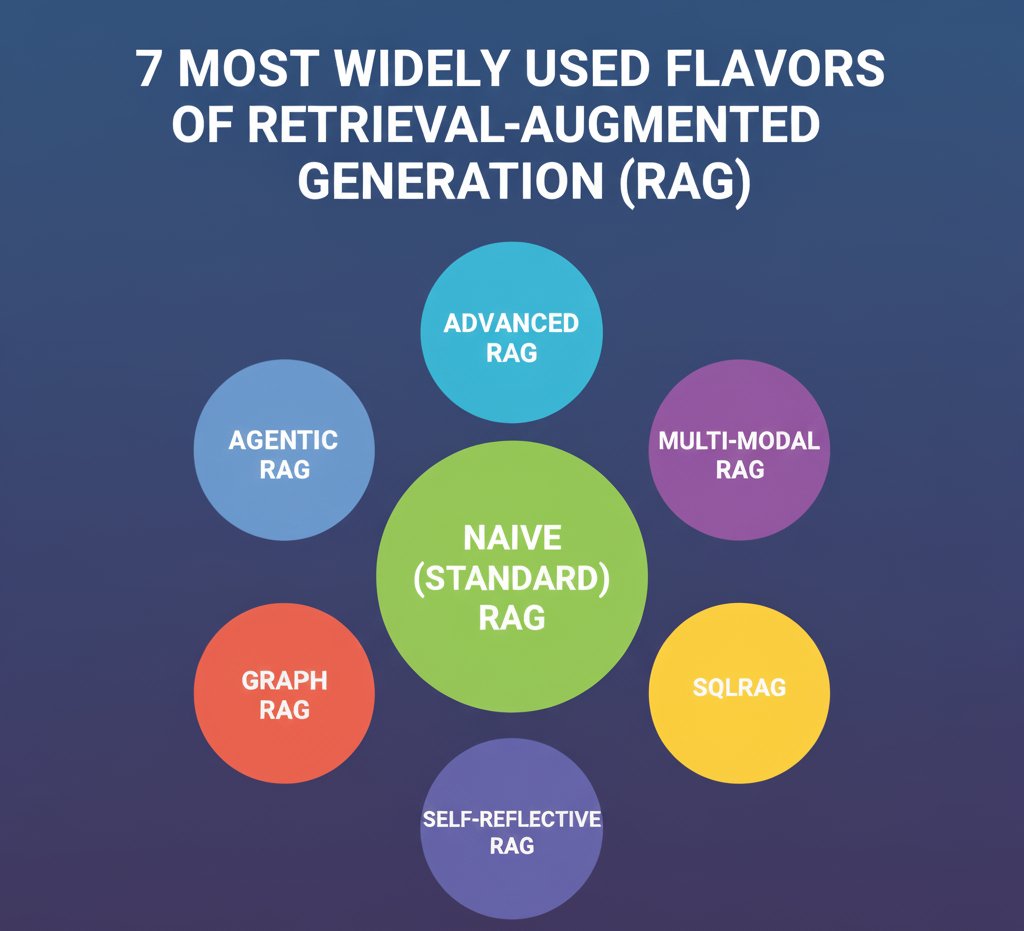
Figure 1: RAG Flavours
- Naive (Standard) RAG
Standard RAG is the original retrieval-augmented generation approach: a user query is embedded, a single-step search over a vector database retrieves the top-K text chunks, and those chunks plus the query are fed directly into an LLM to generate an answer.
In this simplest pipeline there is minimal preprocessing or post-processing, retrieved documents are passed straight to the model without filtering or reranking.
The result is a fast, straightforward pipeline for adding external knowledge to LLMs.
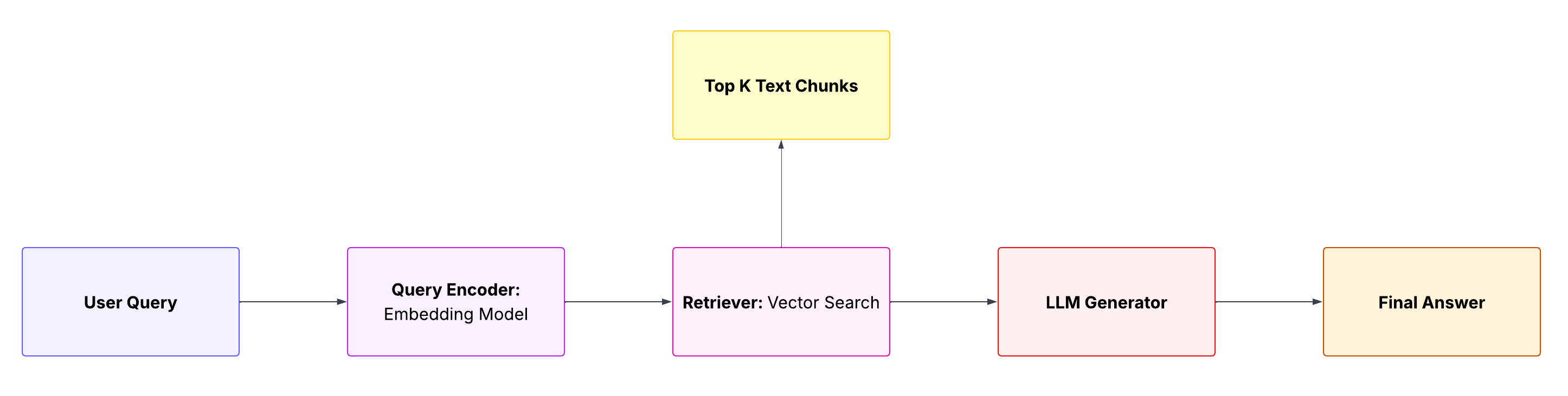
Figure 2: Naive RAG
Good Aspects: It excels at speed and simplicity (low latency and cost) because it performs just a single vector search and one LLM call.
Bad Aspects: Its generation quality is only as good as the initial retrieval: it can struggle with complex or ambiguous questions and has no built-in verification step, so irrelevant or outdated chunks may be included.
Use Cases: Basic conversational agents and FAQ systems, simple document Q&A, or any scenario where queries are well-scoped and high precision isn’t critical.
- Advanced RAG
Advanced RAG refers to production-ready RAG pipelines that augment the naive flow with multiple processing stages.
For example, modern RAG systems may rewrite or expand queries, employ both semantic (vector) and keyword (BM25) search, re-rank retrieved passages with a cross-encoder, and even loop back to re-query or filter results.

Figure 3: Advanced RAG
Good Aspects: By adding reranking, chain-of-thought verification, or tool-augmented steps, advanced RAG achieves higher answer accuracy and relevance.
Bad Aspects: It has higher computational cost and latency (often seconds per query) due to multi-step retrieval, larger context assembly, and any re-ranking or validation loops.
Use Cases: High-reliability systems such as legal/medical Q&A, research assistants, or enterprise search where correctness is critical.
- Mult-modal RAG
Multi-Modal RAG extends RAG to handle diverse data types (text, images, audio, videos, etc).
The key idea is to convert non-text inputs into searchable form or embeddings and include them in the retrieval process. For example, images can be converted to captions or feature vectors; videos can be tokenized into descriptive chunks; or separate vector stores can be used for each modality.
The retrieved content may then include textual documents, image captions, or other media features, which the LLM uses (often via a multi-modal model) to generate a unified answer.
This variant is used when queries involve visual or auditory data. Typical applications include answering questions about images (e.g. “What diseases are visible in this X-ray?”), product catalogs (text descriptions + photos), or any scenario combining documents with illustrations. For instance, an AI assistant for engineering manuals might retrieve relevant text and related diagrams simultaneously. In essence, Multi-Modal RAG “looks through all these different media types to find relevant information and combines everything to provide an accurate response”

Figure 4: Multi-modal RAG
Good Aspects: Enables richer answers (“complete answers using different sources”).
Bad Aspects: The pipeline cost and complexity increases (e.g. running vision models or OCR), and storage/indexing must handle heterogeneous embeddings. The added processing yields slower queries and requires much more computation, and the ultimate quality depends on how well each modality is interpreted.
Use Cases: Vision+language QA systems, document analysis (PDFs with images), medical diagnostics (combining patient charts and images), multimedia search, etc.
- Agentic RAG
Agentic RAG uses autonomous agents or tools to augment retrieval. Instead of a single retrieval step, an agentic RAG orchestrates multiple sub-tasks: for example, one tool might query Wikipedia, another might call an API, a calculator agent might compute values, etc. The LLM acts as a controller (“agent”) that plans a multi-step strategy, invoking specialized tools in sequence and synthesizing the results.
Architecturally, it’s like a RAG pipeline with an extra decision layer (the agent) that can do loops or branching.
By “delegating work to specialized components,” it can improve performance on complex Q&A by piecing together diverse information.
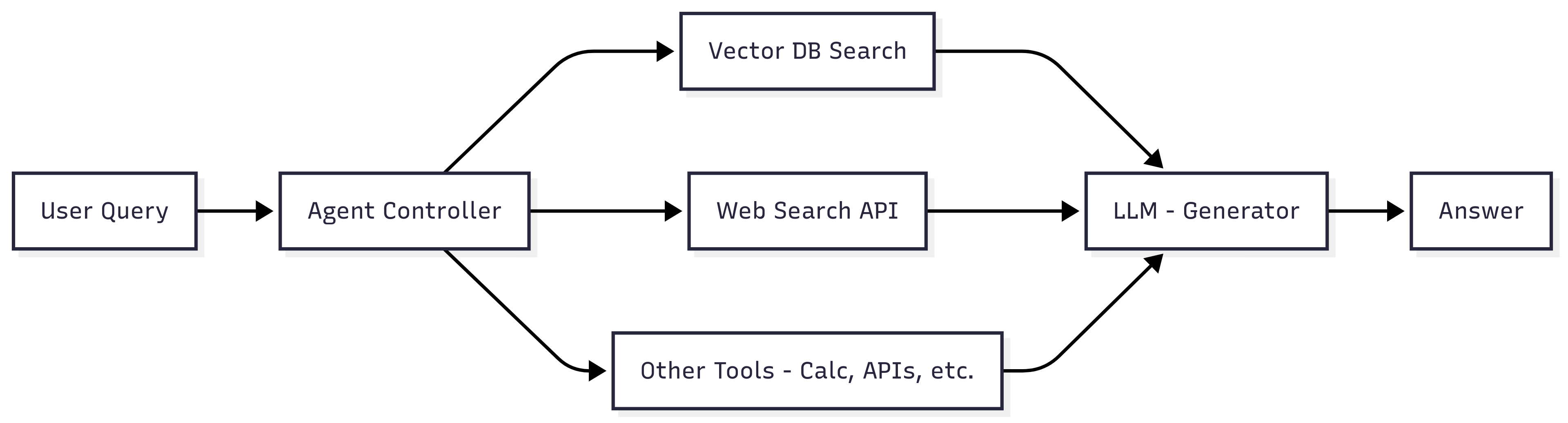
Figure 5: Agentic RAG
Good Aspects: Higher answer quality for complicated tasks (multi-step reasoning, tool execution).
Bad Aspects: Agentic RAG “makes intelligent decisions about information gathering” but “costs more to run due to multiple searches” and “takes longer to respond”.
Use Cases: Complex enterprise assistants (legal research, multi-source analytics), advanced customer support, or any task requiring tool-use (calendar lookup, database queries, etc.)
- SQLRAG
SQLRAG is a RAG variant specialized for database querying. It uses an LLM to translate a natural-language query into SQL, executes that SQL on a connected database, and returns the results (often with both the generated SQL and database response).
The pipeline typically involves:
- Semantic retrieval over database metadata (table/column descriptions) to identify relevant tables
- Having the LLM generate a SQL query
- Running the query and returning both the answer and the SQL code
Some systems add a feedback loop: if the SQL fails, the error is fed back to the LLM for correction. By leveraging RAG over metadata (catalogs) and LLMs, SQLRAG makes complex SQL generation more reliable.

Figure 6: SQLRAG
Good Aspects: Enables non-experts to query structured data.
Bad Aspects: In general it adds overhead (database query time and natural language generation).
Use Cases: It’s used for business intelligence, data analytics, and dashboarding, turning database access into conversational Q&A.
- GraphRAG
GraphRAG combines RAG with a knowledge graph. Instead of treating documents as isolated text chunks, it builds a graph of entities and relationships (from the data or documents) and uses graph queries to retrieve context. Queries can directly traverse the graph (e.g. multi-hop path queries) to fetch relevant information.
It allows retrieval that respects entity relationships: for instance, finding all drug compounds connected to a disease and their clinical trials, rather than just keyword matching or semantic matching separate papers.
GraphRAG is suited to domains with rich structured knowledge. For example, in investigative journalism or business intelligence, where uncovering hidden connections is key, GraphRAG can retrieve multi-hop answers that span the graph.

Figure 7: GraphRAG
Good Aspects: Excellent multi-hop reasoning and explainability.
Bad Aspects: Retrieval can be slower and more complex, since graph search or multiple query steps are needed. Building the underlying graph is also labor-intensive (often requiring NLP or human curation).
Use Cases: Queries requiring deep relational context: e.g. “Which suppliers are linked to Company X’s product line and how has their pricing changed?” or personalized recommendation queries over user–item graphs. GraphRAG excels when the answer depends on combining connected entities rather than keyword matches.
- Self-Reflective RAG
Self-Reflective RAG (often called Self-RAG) augments the RAG process with an internal feedback loop.
Instead of stopping at a single retrieval, Self-RAG first generates an answer from the documents it pulls in, then runs that answer through evaluation modules to verify accuracy and alignment with the sources. Along the way, the model may reformulate the original query filling in missing context or implied intent from the conversation to sharpen the search and improve the final response.

Figure 8: Self-reflection RAG
Good Aspects: Self-reflection boosts generation quality (higher factual accuracy and citation precision).
Bad Aspects: The model may run multiple retrievals and generations per query, making it slower and more expensive than standard RAG.
Use Cases: Tasks demanding extremely reliable answers e.g. legal briefs, scientific report generation, or any domain where “answers must be factually grounded”. Anywhere an iterative check-and-retrieve step reduces hallucination.
Conclusion
Each variant trades off complexity vs. capability. Standard RAG is simplest and fastest but limited in nuance. Advanced RAG adds engineering overhead to improve quality. Multi-Modal RAG broadens content support but incurs extra inference cost. Agentic RAG achieves complex, tool-assisted answers but with higher latency. SQLRAG specializes in structured data, scaling with database performance. GraphRAG excels at relational queries via knowledge graphs, but building/maintaining graphs is intensive. Self-Reflective RAG delivers the most reliable answers (via iterative checking) at the price of additional runtime.